| AI: 机器学习必须懂的几个术语:Label、Feature、Model... | 您所在的位置:网站首页 › a new的意思 › AI: 机器学习必须懂的几个术语:Label、Feature、Model... |
AI: 机器学习必须懂的几个术语:Label、Feature、Model...
|
AI: 机器学习必须懂的几个术语:Label、Feature、Model...
1.标签 Label2.特征 Feature3.样本 Example3.1有标签样本(labeled):3.2无标签样本(unlabeled):
4.模型 Model5.回归 Regression6.分类 Classification7.机器学习算法地图博主热门文章推荐:
1.标签 Label
标签:所预测的东东实际是什么(可理解为结论),如线性回归中的 y 变量,如分类问题中图片中是猫是狗(或图片中狗的种类)、房子未来的价格、音频中的单词等等任何事物,都属于Label。 (如一组图片,已经表明了哪些是狗,哪些是猫,这里Label就是分类问题中每一个类) 特征是事物固有属性,可理解为做出某个判断的依据,如人的特征有长相、衣服、行为动作等等,一个事物可以有N多特征,这些组成了事物的特性,作为机器学习中识别、学习的基本依据。 其中机器学习重要步骤:特征提取就是通过多种方式,对数据的特征数据进行提取。一般,特征数据越多,训练的机器学习模型就会越精确,但处理难度也越大。 3.样本 Example样本是指一组或几组数据,样本一般作为训练数据来训练模型 样本分为以下两类: 有标签样本无标签样本 3.1有标签样本(labeled):同时包含特征和标签 例如以下房价数据集: 包含特征,但不包含标签 如以下数据集: 去掉了Label,但是一样有用(如用在测试训练后的模型,即训练好模型后,输入该数据,那到预测后的房价与原标签进行比较,得到模型误差) 模型定义了特征与标签之间的关系,就是我们机器学习的一组数据关系表示,也是我们学习机器学习的核心 例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。 模型生命周期的两个重要阶段: 训练 Training是指创建或学习模型。也就是说,向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值 推断 Inference是指将训练后的模型应用于无标签样本。也就是说,使用经过训练的模型做出有用的预测 (y’)。例如,模型训练好后,就可以使用模型进行Inference ,可以针对新的无标签样本预测房价medianHouseValue。 回归就是我们数学学习的线性方程,是一种经典函数逼近算法。 在机器学习中,就是根据数据集,建立一个线性方程组,能够无线逼近数据集中的数据点,是一种基于已有数据关系实现预测的算法。 回归模型可预测连续值(线性) 例如,回归模型做出的预测可回答如下问题: 某小区房价的趋势?用户点击此广告的概率是多少?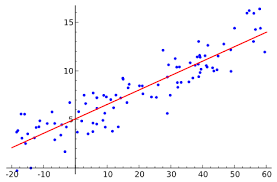 当机器学习模型最终目标(模型输出)是求一个具体数值时,例如房价的模型输出为25000,则大多数可以通过回归问题来解决。 线性回归的好处在与模型简单,计算速度快,方便应用在分布式系统对大数据进行处理。 线性回归还有个姐妹:逻辑回归(Logistic Regression),主要应用在分类领域
6.分类 Classification 当机器学习模型最终目标(模型输出)是求一个具体数值时,例如房价的模型输出为25000,则大多数可以通过回归问题来解决。 线性回归的好处在与模型简单,计算速度快,方便应用在分布式系统对大数据进行处理。 线性回归还有个姐妹:逻辑回归(Logistic Regression),主要应用在分类领域
6.分类 Classification
顾名思义,分类模型可用来预测离散值 例如,分类模型做出的预测可回答如下问题: 是/否问题,某个指定电子邮件是垃圾邮件还是非垃圾邮件?图片是动物还是人?垃圾分类
当机器学习模型最终目标(模型输出)是布尔或一定范围的数时,例如判断一张图片是不是人,模型输出0/1:0不是,1是;又例如垃圾分类,模型输出1-10之间的整数,1代表生活垃圾,2代表厨余垃圾。。等等,这类需求则大多数可以通过分类问题来解决。 7.机器学习算法地图机器学习算法多种多样,许多情况下,建模和算法设计是Designer所选择的,具体采用哪种算法也没有一定要求,根据实际具体问题具体分析。 (单击可以放大图片)
一篇读懂系列: 一篇读懂无线充电技术(附方案选型及原理分析)一篇读懂:Android/iOS手机如何通过音频接口(耳机孔)与外设通信一篇读懂:Android手机如何通过USB接口与外设通信(附原理分析及方案选型)LoRa Mesh系列: LoRa学习:LoRa关键参数(扩频因子,编码率,带宽)的设定及解释LoRa学习:信道占用检测原理(CAD)LoRa/FSK 无线频谱波形分析(频谱分析仪测试LoRa/FSK带宽、功率、频率误差等)网络安全系列: ATECC508A芯片开发笔记(一):初识加密芯片SHA/HMAC/AES-CBC/CTR 算法执行效率及RAM消耗 测试结果常见加密/签名/哈希算法性能比较 (多平台 AES/DES, DH, ECDSA, RSA等)AES加解密效率测试(纯软件AES128/256)–以嵌入式Cortex-M0与M3 平台为例嵌入式开发系列: 嵌入式学习中较好的练手项目和课题整理(附代码资料、学习视频和嵌入式学习规划)IAR调试使用技巧汇总:数据断点、CallStack、设置堆栈、查看栈使用和栈深度、Memory、Set Next Statement等Linux内核编译配置(Menuconfig)、制作文件系统 详细步骤Android底层调用C代码(JNI实现)树莓派到手第一步:上电启动、安装中文字体、虚拟键盘、开启SSH等Android/Linux设备有线&无线 双网共存(同时上内、外网)AI / 机器学习系列: AI: 机器学习必须懂的几个术语:Label、Feature、Model…AI:卷积神经网络CNN 解决过拟合的方法 (Overcome Overfitting)AI: 什么是机器学习的数据清洗(Data Cleaning)AI: 机器学习的模型是如何训练的?(在试错中学习)数据可视化:TensorboardX安装及使用(安装测试+实例演示) |

 特征是机器学习模型的输入变量。如线性回归中的 x 变量。
特征是机器学习模型的输入变量。如线性回归中的 x 变量。 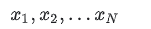 例如在垃圾邮件分类问题中,特征可能包括:
例如在垃圾邮件分类问题中,特征可能包括: 在监督学习中利用数据做训练时,有标签数据/样本(Labeled data)或叫有/无标记数据,就是指有没有将数据归为要预测的类别。
在监督学习中利用数据做训练时,有标签数据/样本(Labeled data)或叫有/无标记数据,就是指有没有将数据归为要预测的类别。 其中包含特征:卧室数量等,最右边一列是标签:房价中间值 (注,因为该问题要预测未来房价走势,所以Label就是某条房屋数据中的房价)
其中包含特征:卧室数量等,最右边一列是标签:房价中间值 (注,因为该问题要预测未来房价走势,所以Label就是某条房屋数据中的房价)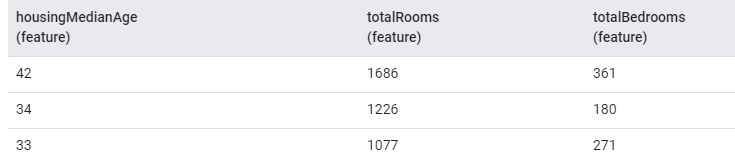 在使用有标签样本训练模型之后,我们会使用该模型预测无标签样本的标签。在垃圾邮件检测器示例中,无标签样本是用户尚未添加标签的新电子邮件。
在使用有标签样本训练模型之后,我们会使用该模型预测无标签样本的标签。在垃圾邮件检测器示例中,无标签样本是用户尚未添加标签的新电子邮件。


【本文地址】